Unpacking CVE-2021-40444: A Deep Technical Analysis of an Office RCE Exploit

In the middle of August 2021, a special Word document was uploaded to VirusTotal by a user from Argentina. Although it was only detected by a single antivirus engine at the time, this sample turned out to be exploiting a zero day vulnerability in Microsoft Office to gain remote code execution.
Three weeks later, Microsoft published an advisory after being notified of the exploit by researchers from Mandiant and EXPMON. It took Microsoft nearly a month from the time the exploit was first uploaded to VirusTotal to publish a patch for the zero day.
In this blog post, I will be sharing my in-depth analysis of the several vulnerabilities abused by the attackers, how the exploit was patched, and how to port the exploit for a generic Internet Explorer environment.
First Look
A day after Microsoft published their advisory, I saw a tweet from the malware collection group @vxunderground offering a malicious payload for CVE-2021-40444 to blue/red teams.
I reached out to receive a copy, because why not? My curiosity has generally lead me in the right direction for my life and I was interested in seeing a Microsoft Word exploit that had been found in the wild.

With the payload in hand, one of the first steps I took was placing it into an isolated virtual machine with basic dynamic analysis tooling. Specifically, one of my favorite network monitoring utilities is Fiddler, a freemium tool that allows you to intercept web requests (including encrypted HTTPS traffic).
After I opened the malicious Word document, Fiddler immediately captured strange HTTP requests to the domain, "hidusi[.]com". For some reason, the Word document was making a request to "http://hidusi[.]com/e8c76295a5f9acb7/side.html".
At this point, the "hidusi[.]com" domain was already taken down. Fortunately, the "side.html" file being requested was included with the sample that was shared with me.
Unfortunately, the HTML file was largely filled with obfuscated JavaScript. Although I could immediately decrypt this JavaScript and go from there, this is generally a bad idea to do at an early stage because we have no understanding of the exploit.
Reproduction
Whenever I encounter a new vulnerability that I want to reverse engineer, my first goal is always to produce a minimal reproduction example of the exploit to ensure I have a working test environment and a basic understanding of how the exploit works. Having a reproduction case is critical to reverse engineering how the bug works, because it allows for dynamic analysis.
Since the original "hidusi[.]com" domain was down, we needed to host our version of side.html. Hosting a file is easy, but how do we make the Word document use our domain instead? It was time to find where the URL to side.html was hidden inside the Word document.

Did you know that Office documents are just ZIP files? As we can see from the bytes of the malicious document, the first few bytes are simply the magic value in the ZIP header.
Once I extracted the document as a ZIP, finding the URL was relatively easy. I performed a string search across every file the document contained for the domain "hidusi[.]com".
Sure enough, I found one match inside the file "word/_rels/document.xml.rels". This file is responsible for defining relationships associated with embedded objects in the document.
OLE objects are part of Microsoft's proprietary Object Linking and Embedding technology, which allows external documents, such as an Excel spreadsheet, to be embedded within a Word document.

The relationship that contained the malicious URL was an external OLE object with a strange "Target" attribute containing the "mhtml" protocol. Let's unpack what's going on in this value.
- In red, we see the URL Protocol "mhtml".
- In green, we see the malicious URL our proxy caught.
- In blue, we see an interesting "!x-usc" suffix appended to the malicious URL.
- In purple, we see the same malicious URL repeated.
Let's investigate each piece one-by-one.
Reproduction: What's "MHTML"?
A useful tool I've discovered in past research is URLProtocolView from Nirsoft. At a high level, URLProtocolView allows you to list and enumerate the URL protocols installed on your machine.

The MHTML protocol used in the Target attribute was a Pluggable Protocol Handler, similar to HTTP. The inetcomm.dll module was responsible for handling requests to this protocol.

Unlike MHTML however, the HTTP protocol is handled by the urlmon.dll module.

When I was researching past exploits involving the MHTML protocol, I came across an interesting article all the way back from 2011 about CVE-2011-0096. In this case, a Google engineer publicly disclosed an exploit that they suspected malicious actors attributed to China had already discovered. Similar to this vulnerability, CVE-2021-0096 was only found to be used in "very targeted" attacks.
When I was researching implementations of exploits for CVE-2011-0096, I came across an exploit-db release that included an approach for abusing the vulnerability through a Word document. Specifically, in part #5 and #6 of the exploit, this author discovered that CVE-2011-0096 could be abused to launch executables on the local machine and read the contents of the local filesystem. The interesting part here is that this 2011 vulnerability involved abusing the MHTML URL protocol and that it allowed for remote code execution via a Word document, similar to the case with CVE-2021-4044.
Reproduction: What about the "X-USC" in the Target?
Going back to our strange Target attribute, what is the "!x-usc:" portion for?
I found a blog post from 2018 by @insertScript which discovered that the x-usc directive was used to reference an external link. In fact, the example URL given by the author still works on the latest version of Internet Explorer (IE). If you enter "mhtml:http://google.com/whatever!x-usc:http://bing.com" into your IE URL bar while monitoring network requests, there will be both a request to Google and Bing, due to the "x-usc" directive.
In the context of CVE-2021-40444, I was unable to discover a definitive answer for why the same URL was repeated after an "x-usc" directive. As we'll see in upcoming sections, the JavaScript in side.html is executed regardless of whether or not the attribute contains the "x-usc" suffix. It is possible that due to some potential race conditions, this suffix was added to execute the exploit twice to ensure successful payload delivery.
Reproduction: Attempting to Create my Own Payload
Now that we know how the remote side.html page is triggered by the Word document, it was time to try and create our own. Although we could proceed by hosting the same side.html payload the attackers used in their exploit, it is important to produce a minimal reproduction example first.
Instead of hosting the second-stage side.html payload, I opted to write a barebone HTML page that would indicate JavaScript execution was successful. This way, we can understand how JavaScript is executed by the Word document before reverse engineering what the attacker's JavaScript does.
In the example above, I created an HTML page that simply made an XMLHttpRequest to a non-existent domain. If the JavaScript is executed, we should be able to see a request to "icanseethisrequestonthenetwork.com" inside of Fiddler.
Before testing in the actual Word document, I verified as a sanity check that this page does make the web request inside of Internet Explorer. Although the code may seem simple enough to where it would "obviously work", performing simple sanity checks like these on fundamental assumptions you make can greatly save you time debugging future issues. For example, if you don't verify a fundamental assumption and continue with reverse engineering, you could spend hours debugging the wrong issue when in fact you were missing a basic mistake.

Once I patched the original Word document with my modified relationship XML, I launched it inside my VM with the Fiddler proxy running. I was seeing requests to the send_request.html payload! But... there were no requests to "icanseethisonthenetwork.com". We have demonstrated a flaw in our fundamental assumption that whatever HTML page we point the MHTML protocol towards will be executed.
How do you debug an issue like this? One approach would be to go in blind and try to reverse engineer the internals of the HTML engine to see why JavaScript wasn't being executed. The reason this is not a great idea is because often these codebases can be massive, and it would be like finding a needle in a haystack.
What can we do instead? Create a minimally viable reproduction case where the JavaScript of the HTML is executed. We know that the attacker's payload must have worked in their attack. What if instead of writing our own payload first, we tried to host their payload instead?
I uploaded the attacker’s original "side.html" payload to my server and replaced the relationship in the Word document with that URL. When I executed this modified document in my VM, I saw something extremely promising- requests for "ministry.cab". This means that the attacker's JavaScript inside side.html was executed!
We have an MVP payload that gets executed by the Word document, now what? Although we could ignore our earlier problem with our own payload and try to figure out what the CAB file is used for directly, we'd be skipping a crucial step of the exploit. We want to understand CVE-2021-40444, not just reproduce it.
With this MVP, we can now try to debug and reverse engineer the question, "Why does the working payload result in JavaScript execution, but not our own sample?".
Reproduction: Reverse Engineering Microsoft’s HTML Engine
The primary module responsible for processing HTML in Windows is MSHTML.DLL, the "Microsoft HTML Viewer". This binary alone is 22 MB, because it contains almost everything from rendering HTML to executing JavaScript. For example, Microsoft has their own JavaScript engine in this binary used in Internet Explorer (and Word).
Given this massive size, blindly reversing is a terrible approach. What I like to do instead is use ProcMon to trace the execution of the successful (document with side.html) and failing payload (document with barebone HTML), then compare their results. I executed the attacker payload document and my own sample document while monitoring Microsoft Word with ProcMon.
With the number of operations an application like Microsoft Office makes, it can be difficult to sift through the noise. The best approach I have for this problem is to use my context to find relevant operations. In this case, since we were looking into the execution of JavaScript, I looked for operations involving the word “script”.
You might think, what can we do with relevant operations? An insanely useful feature of ProcMon is the ability to see the caller stack for a given operation. This lets you see what executed the operation.
It looked like the PostManExecute function was primary responsible for triggering the complete execution of our payload. Using IDA Pro, I set a breakpoint on this function and opened both the successful/failing payloads.
I found that when the success payload was launched, PostManExecute would be called, and the page would be loaded. On the failure case however, PostManExecute was not called and thus the page was never executed. Now we needed to figure out why is PostManExecute being invoked for the attacker’s payload but not ours?
Going back to the call stack, what’s interesting is that PostManExecute seems to be the result of a callback that is being invoked in an asynchronous thread.

Looking at the cross references for the function called right after the asynchronous dispatcher, CDwnChan::OnMethodCall, I found that it seemed to be queued in another function called CDwnChan::Signal.

CDwnChan::Signal seemed to be using the function "_GWPostMethodCallEx" to queue the CDwnChan::OnMethodCall to be executed in the asynchronous thread we saw. Unfortunately, this Signal function is called from many places, and it would be a waste of time to try to statically reverse engineer every reference.
What can we do instead? Looking at the X-Refs for _GWPostMethodCallEx, it seemed like it was used to queue almost everything related to HTML processing. What if we hooked this function and compared the different methods that were queued between the success and failure path?
Whenever __GWPostMethodCallEx was called, I recorded the method being queued for asynchronous execution and the call stack. The diagram above demonstrates the methods that were queued during the execution of the successful payload and the failing payload. Strangely in the failure path, the processing of the HTML page was terminated (CDwnBindData::TerminateOnApt) before the page was ever executed.
Why was the Terminate function being queued before the OnMethodCall function in the failure path? The call stacks for the Terminate function matched between the success and failure paths. Let’s reverse engineer those functions.
When I debugged the CDwnBindData::Read function, which called the Terminate function, I found that a call to CDwnStm::Read was working in the success path but returning an error in the failure path. This is what terminated the page execution for our sample payload!
The third argument to CDwnStm::Read was supposed to be the number of bytes the client should try to read from the server. For some reason, the client was expecting 4096 bytes and my barebone HTML file was not that big.
As a sanity check, I added a bunch of useless padding to the end of my HTML file to make its size 4096+ bytes. Let’s see our network requests with this modified payload.


We had now found and fixed the issue with our barebone HTML page! But our work isn't over yet. We wouldn’t be great reverse engineers if we didn’t investigate why the client was expecting 4096 bytes in the first place.
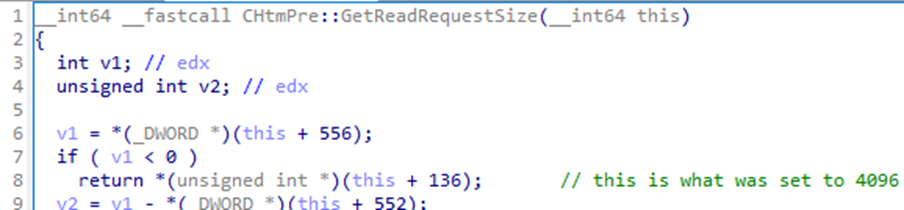
I traced back the origin of the expected size to a call in CHtmPre::Read to CHtmPre::GetReadRequestSize. Stepping through this function in a debugger, I found that a field at offset 136 of the CHtmPre class represented the request size the client should expect. How can we find out why this value is 4096? Something had to write to it at some point.

Since we were looking at a class function of the CHtmPre class, I set a breakpoint on the constructor for this class. When the debugger reached the constructor, I placed a write memory breakpoint for the field offset we saw (+ 136).

The breakpoint hit! And not so far away either. The 4096 value was being set inside of another object constructor, CEncodeReader::CEncodeReader. This constructor was instantiated by the CHtmPre constructor we just hooked. Where did the 4096 come from then? It was hardcoded into the CHtmPre constructor!

What was happening was that when the CHtmPre instance was constructed, it had a default read size of 4096 bytes. The client was reading the bytes from the HTTP response before this field was updated with the real response size. Since our barebone payload was just a small HTML page under 4096 bytes, the client thought that the server hadn’t sent the required response and thus terminated the execution.
The reason the attacker's payload worked is because it was above 4096 bytes in size. We just found a bug still present in Microsoft’s HTML processor!
Reproduction: Fixing the Attacker's Payload
We figured out how to make sure our payload executes. If you recall to an earlier section of this blog post, we saw that a request to a "ministry.cab" file was being made by the attacker's side.html payload. Fortunately for us, the attacker’s sample came with the CAB file the server was originally serving.
This CAB file was interesting. It had a single file named "../msword.inf", suggesting a relative path escape attack. This INF file was a PE binary for the attacker’s Cobalt Strike beacon. I replaced this file with a simple DLL that opened Calculator for testing. Unfortunately, when I uploaded this CAB file to my server, I saw a successful request to it but no Calculator.
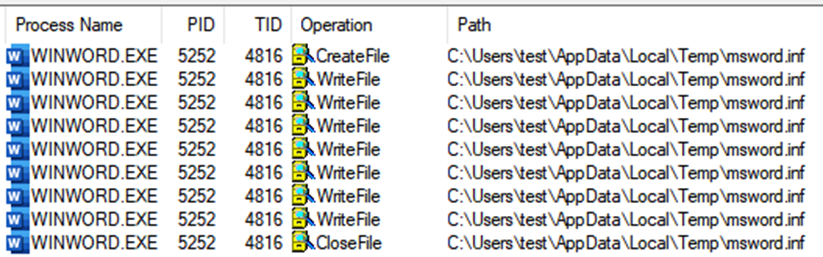
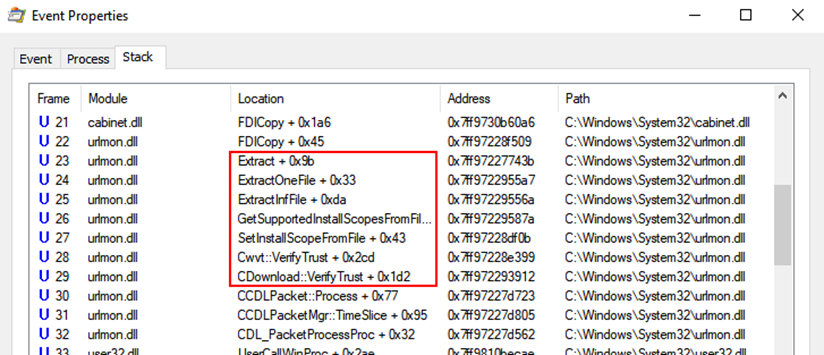
I monitored Word with ProcMon once again to try and see what was happening with the CAB file. I filtered for "msword.inf" and found interesting operations where Word was writing it to the VM user's %TEMP% directory. The "VerifyTrust" function name in the call stack suggested that the INF file was written to the TEMP directory while it was trying to verify its signature.
Let's step through these functions to figure out what's going on.
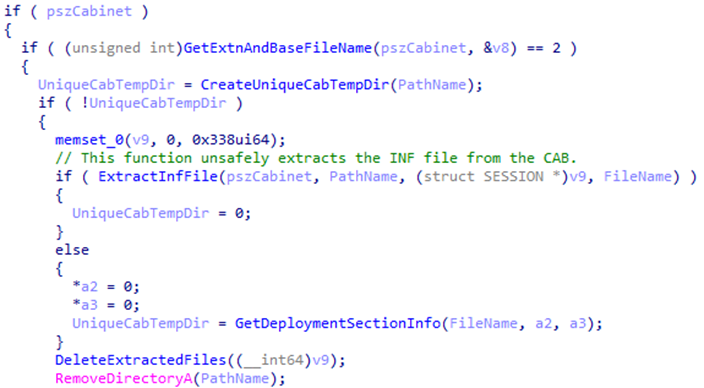
After stepping through Cwvt::VerifyTrust with a debugger, I found that the function attempted to verify the signature of files contained within the CAB file. Specifically, if the CAB file included an INF file, it would extract it to disk and try to verify its digital signature.
What was happening was that the extraction process didn't have any security measures, allowing for an attacker to use relative path escapes to get out of the temporary directory that was generated for the CAB file.
The attackers were using a zero-day with ActiveX controls:
- The attacker’s JavaScript (side.html) would attempt to execute the CAB file as an ActiveX control.
- This triggered Microsoft’s security controls to verify that the CAB file was signed and safe to execute.
- Unfortunately, Microsoft handled this CAB file without care and although the signature verification fails, it allowed an attacker to extract the INF file to another location with relative path escapes.
If there was a user-writable directory where if you could put a malicious INF file, it would execute your malware, then they could have stopped here with their exploit. This isn’t a possibility though, so they needed some way to execute the INF file as a PE binary.
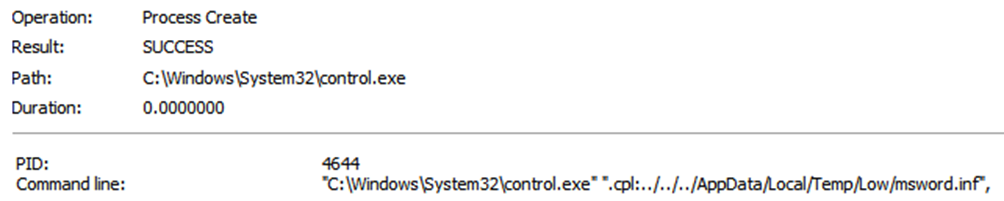

Going back to ProcMon, I tried to see why the INF file wasn’t being executed. It looks like they were using another exploit to trigger execution of "control.exe".

The attackers were triggering the execution of a Control Panel Item. The command line for control.exe suggested they were using the ".cpl" file extension as a URL protocol and then used relative path escapes to trigger the INF file.
Why wasn’t my Calculator DLL being executed then? Entirely my mistake! I was executing the Word document from a nested directory, but the attackers were only spraying a few relative path escapes that never reached my user directory. This makes sense because this document is intended to be executed from a victim's Downloads folder, whereas I was hosting the file inside of a nested Documents directory.
I placed the Word document in my Downloads folder and… voila:
Reversing the Attacker's Payload
We have a working exploit! Now the next step to understanding the attack is to reverse engineer the attacker’s malicious JavaScript. If you recall, it was somewhat obfuscated. As someone with experience with JavaScript obfuscators, it didn’t seem like the attacker’s did too much, however.
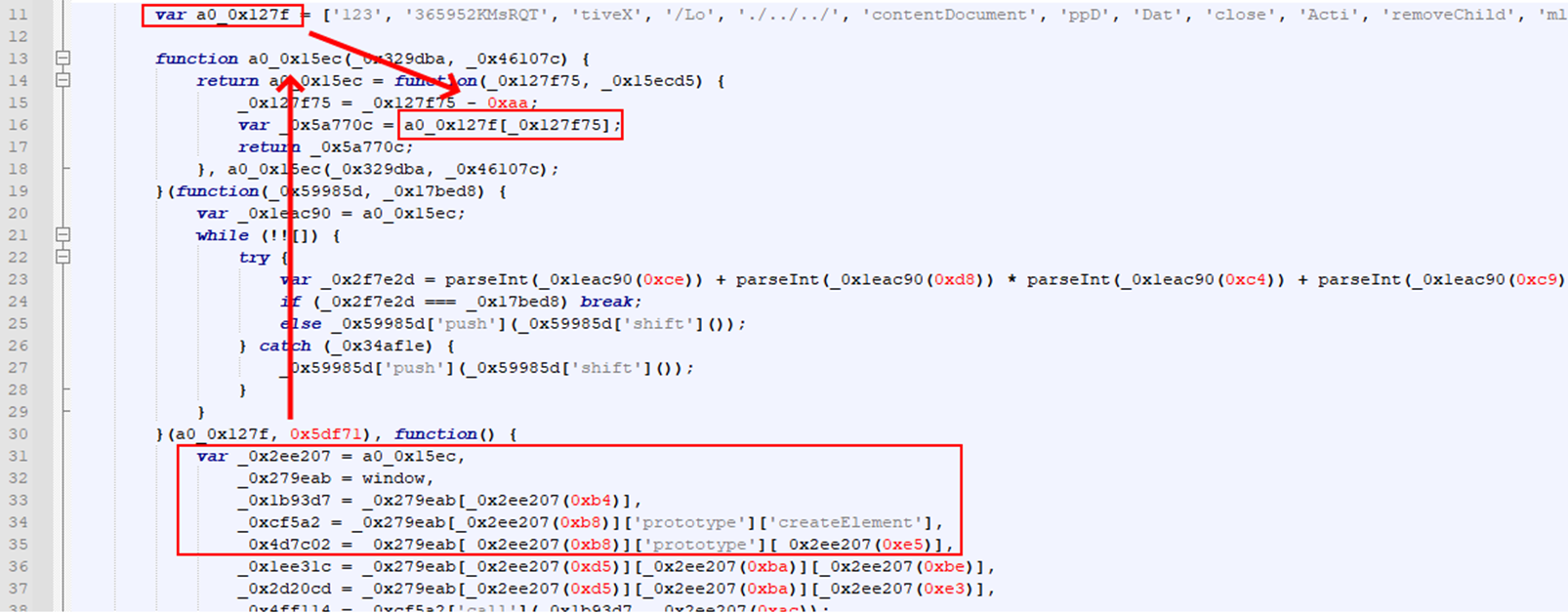
A common pattern I see with attempts at string obfuscation in JavaScript is an array containing a bunch of strings and the rest of the code referencing strings through an unknown function which referenced that array.
In this case, we can see a string array named "a0_0x127f" which is referenced inside of the global function "a0_0x15ec". Looking at the rest of the JavaScript, we can see that several parts of it call this unknown function with an numerical index, suggesting that this function is used to retrieve a deobfuscated version of the string.
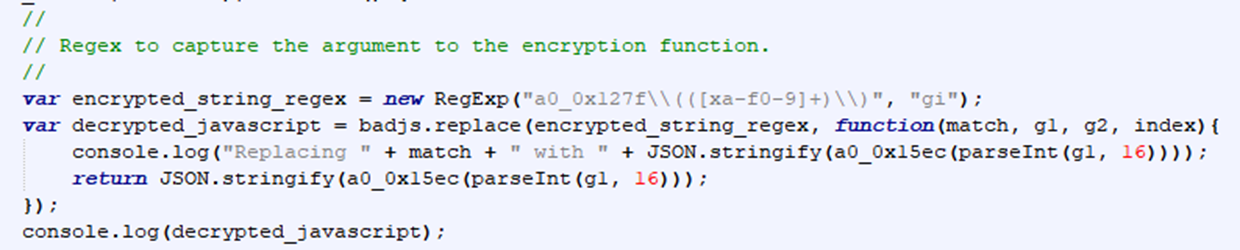
This approach to string obfuscation is relatively easy to get past. I wrote a small script to find all calls to the encryption function, resolve what the string was, and replace the entire call with the real string. Instead of worrying about the mechanics of the deobfuscation function, we can just call into it like the real code does to retrieve the deobfuscated string.
This worked extremely well and we now have a relatively deobfuscated version of their script. The rest of the deobfuscation was just combining strings, getting rid of "indirect" calls to objects, and naming variables given their context. I can’t cover each step in detail because there were a lot of minor steps for this last part, but there was nothing especially notable. I tried naming the variables the best I could given the context around them and commented out what I thought was happening.
Let’s review what the script does.

In this first part, the attacker's created an iframe element, retrieved the ActiveX scripting interface for that iframe, and destroyed the iframe. Although the iframe has been destroyed, the ActiveX interface is still live and can be used to execute arbitrary HTML/JavaScript.
In this next part, the attackers used the destroyed iframe's ActiveX interface to create three nested HTML documents. I am not entirely sure what the purpose of these nested documents serves, because if the attackers only used the original ActiveX interface without any nesting, the exploit works fine.
This final section is what performs the primary exploits.
The attackers make a request to the exploit CAB file ("ministry.cab") with an XMLHttpRequest. Next, the attackers create a new ActiveX Control object inside of the third nested HTML document created in the last step. The class ID and version of this ActiveX control are arbitrary and can be changed, but the important piece is that the ActiveX Control points at the previously requested CAB file. URLMON will automatically verify the signature of the ActiveX Control CAB file, which is when the malicious INF file is extracted into the user's temporary directory.
To trigger their malicious INF payload, the attackers use the ".cpl" file extension as a URL Protocol with a relative path escape in a new HTML document. This causes control.exe to start rundll32.exe, passing the INF file as the Control Panel Item to execute.
The fully deobfuscated and commented HTML/JS payload can be found here.
Overview of the Attack
We covered a significant amount in the previous sections, let's summarize the attack from start to finish:
- A victim opens the malicious Word document.
- Word loads the attacker's HTML page as an OLE object and executes the contained JavaScript.
- An IFrame is created and destroyed, but a reference to its ActiveX scripting surface remains.
- The CAB file is invoked by creating an ActiveX control for it.
- While the CAB file's signature is verified, the contained INF file is written to the user's Temp directory.
- Finally, the INF is invoked by using the ".cpl" extension as a URL protocol, using relative path escapes to reach the temporary directory.
Reversing Microsoft's Patch
When Microsoft released its advisory for this bug on September 7th, they had no patch! To save face, they claimed Windows Defender was a mitigation, but that was just a detection for the attacker's exploit. The underlying vulnerability was untouched.
It took them nearly a month from when the first known sample was uploaded to VirusTotal (August 19th) to finally fix the issue on September 14th with a Patch Tuesday update. Let’s take a look at the major changes in this patch.
A popular practice by security researchers is to find the differences in binaries that used to contain vulnerabilities with the patched binary equivalent. I updated my system but saved several DLL files from my unpatched machine. There are a couple of tools that are great for finding assembly-level differences between two similar binaries.
I went with Diaphora because it is more advanced than BinDiff and allows for easy pseudo-code level comparisons. The primary binaries I diff'd were:
- IEFRAME.dll - This is what executed the URL protocol for ".cpl".
- URLMON.dll - This is what had the CAB file extraction exploit.
Reversing Microsoft's Patch: IEFRAME
Once I diff’d the updated and unpatched binary, I found ~1000 total differences, but only ~30 major changes. One function that had heavy changes and was associated with the CPL exploit was _AttemptShellExecuteForHlinkNavigate.
In the old version of IEFRAME, this function simply used ShellExecuteW to open the URL protocol with no verification. This is why the CPL file extension was processed as a URL protocol.
In the new version, they added a significant number of checks for the URL protocol. Let’s compare the differences.
In the patched version of _AttemptShellExecuteForHlinkNavigate, the primary addition that prevents the use of file extensions as URL Protocols is the call to IsValidSchemeName.
This function takes the URL Protocol that is being used (i.e ".cpl") and verifies that all characters in it are alphanumerical. For example, this exploit used the CPL file extension to trigger the INF file. With this patch, ".cpl" would fail the IsValidSchemeName function because it contains a period which is non-alphanumerical.
An important factor to note is that this patch for using file extensions as URL Protocols only applies to MSHTML. File extensions are still exposed for use in other attacks against ShellExecute, which is why I wouldn't be surprised if we saw similar techniques in future vulnerabilities.
Reversing Microsoft's Patch: URLMON
I performed the same patch diffing on URLMON and found a major change in catDirAndFile. This function was used during extraction to generate the output path for the INF file.

The patch for the CAB extraction exploit was extremely simple. All Microsoft did was replace any instance of a forward slash with a backslash. This prevents the INF extraction exploit of the CAB file because backslashes are ignored for relative path escapes.
Abusing CVE-2021-40444 in Internet Explorer
Although Microsoft's advisory covers an attack scenario where this vulnerability is abused in Microsoft Office, could we exploit this bug in another context?
Since Microsoft Office uses the same engine Internet Explorer uses to display web pages, could CVE-2021-40444 be abused to gain remote code execution from a malicious page opened in IE? When I tried to visit the same payload used in the Word document, the exploit did not work "out of the box", specifically due to an error with the pop up blocker.

Although the CAB extraction exploit was successfully triggered, the attempt to launch the payload failed because Internet Explorer considered the ".cpl" exploit to be creating a pop up.
Fortunately, we can port the .cpl exploit to get around this pop up blocker relatively easily. Instead of creating a new page, we can simply redirect the current page to the ".cpl" URL.
function redirect() {
//
// Redirect current window without creating new one,
// evading the IE pop up blocker.
//
window.location = ".cpl:../../../AppData/Local/Temp/Low/msword.inf";
document.getElementById("status").innerHTML = "Done";
}
//
// Trigger in 500ms to give time for the .cab file to extract.
//
setTimeout(function() {
redirect()
}, 500);
With the small addition of the redirect, CVE-2021-40444 works without issue in Internet Explorer. The complete code for this ported HTML/JS payload can be found here.
Conclusion
CVE-2021-40444 is in fact compromised of several vulnerabilities as we investigated in this blog post. Not only was there the initial step of extracting a malicious file to a predictable location through the CAB file exploit, but there was also the fact that URL Protocols could be file extensions.
In the latest patch, Word still executes pages with JavaScript if you use the MHTML protocol. What’s frightening to me is that the entire attack surface of Internet Explorer is exposed to attackers through Microsoft Word. That is a lot of legacy code. Time will tell what other vulnerabilities attacker's will abuse in Internet Explorer through Microsoft Office.